Python简易爬虫2-豆瓣电影Top250
前一篇文章总结了一个非常简单的 Python爬虫 –电影票房排行榜,本篇继续总结稍微复杂点的 Python爬虫 -豆瓣电影Top250.
1. 确定爬取目标
这个Case中我们要爬取的目标是豆瓣电影Top250:
网址:https://movie.douban.com/top250
内容:

2. 分析数据源
- 确定网页url:第1页是https://movie.douban.com/top250,第2页是https://movie.douban.com/top250?start=25&filter=,能够发现网址中的start=按25递增
- 确定网页编码:utf-8
- 确定数据位置:数据存储在标签<ol class=’grid_view’>中
3. 开发代码
# 导入要用的包
import numpy as np
import pandas as pd
import re
import requests
from bs4 import BeautifulSoup
# 迭代测试开发,这里省略不写
# 将爬取代码封装到函数中,以便循环调用分页爬取
def get_data(url_str):
# 请求网页
response = requests.get(url_str, headers='') # 需要提供参数headers,不然会请求不到内容
response.encoding = 'utf-8' # 检查网页使用的编码然后指定编码
# 解析网页
text = BeautifulSoup(response.text, "html.parser")
# 提取出标签<ol>
ol = text.find('ol', attrs={'class':'grid_view'})
# 提取出全部的标签<li>
lis = ol.find_all('li')
lis_list = [] # 创建1个空列表用于存储数据
for li in lis:
em = li.find('div', attrs={'class':'item'}).find('div', attrs={'class':'pic'}).find('em') # 排名
title = li.find('div', attrs={'class':'hd'}).find('span', attrs={'class':'title'}) # 标题
bd = li.find('div', attrs={'class':'bd'}) # bd部分
p = bd.find('p') # 电影信息
rating_num = bd.find('div', attrs={'class':'star'}).find('span', attrs={'class':'rating_num'}) # 评分
rating_persons = bd.find('div', attrs={'class':'star'}).find('span', attrs={'class':None, 'content':None, 'property':None}) # 评价人数
quote = bd.find('span', attrs={'class':'inq'}) # 引文
li_list = [em, title, p, rating_num, rating_persons, quote] # 把单个电影的信息存到列表中
lis_list.append(li_list) # 把单个电影信息的列表追加到电影列表中
return lis_list
# 循环爬取10个网页的电影信息
pages_list = []
for i in range(0, 10):
if i == 0:
url_str = 'https://movie.douban.com/top250'
if i >= 1:
url_str = "https://movie.douban.com/top250?start=%d&filter=" % (i * 25)
page_list = get_data(url_str)
pages_list = pages_list + page_list
raw_data = pd.DataFrame(pages_list, dtype='str') # 将数据存到DataFrame中
# 清洗数据
raw_data.to_excel('raw_data.xlsx', index=False) # 导出数据以便观察字符串特征
data = raw_data.copy()
data[0] = data[0].str.extract(r'>(.*)<') # 提取字符>和字符<中间的字符串
data[1] = data[1].str.extract(r'>(.*)<') # 提取字符>和字符<中间的字符串
data[2] = data[2].str.replace('\n', '') # 删除换行符
data[201] = data[2].str.extract(r'导演: (.*)主演') # 提取导演和主演中间的字符串
data[202] = data[2].str.extract(r'主演: (.*)<br') # 提取主演和<br中间的字符串
data[203] = data[2].str.extract(r'导演: (.*)<br') # 提取导演和<br中间的字符串
data[204] = data[201]
data.loc[data[204].isnull(),[204]] = data[203] # 导演和主演的字符太长可能不符合提取规则提取不到导演,这里处理一下
data[205] = data[2].str.extract(r'<br/>(.*)</p>') # 提取<br/>和</p>中间的字符串
df_205 = data[205].str.split(r'/', 2, expand=True) # 按字符/拆分
df_205.columns = [206, 207, 208]
data = pd.concat([data, df_205], axis=1)
data[3] = data[3].str.extract(r'>(.*)<') # 提取字符>和字符<中间的字符串
data[4] = data[4].str.extract(r'(\d+)') # 提取数字
data[5] = data[5].str.extract(r'>(.*)<') # 提取字符>和字符<中间的字符串
data = data[[0, 1, 204, 202, 206, 207, 208, 3, 4, 5]] # 只保留目标数据
for col in data.columns:
data[col] = data[col].str.strip() # 删除每列内容首尾空白符
data.columns = ['排名', '电影名', '导演', '主演', '上映时间', '上映地区', '类型', '评分', '评价人数', '引文'] # 重命名列名
data = data.astype({'排名':'int64', '评分':'float64', '评价人数':'int64'}) # 修改特定列的数据类型
# 保存数据
data.to_excel('data.xlsx', index=False) # 保存到本地
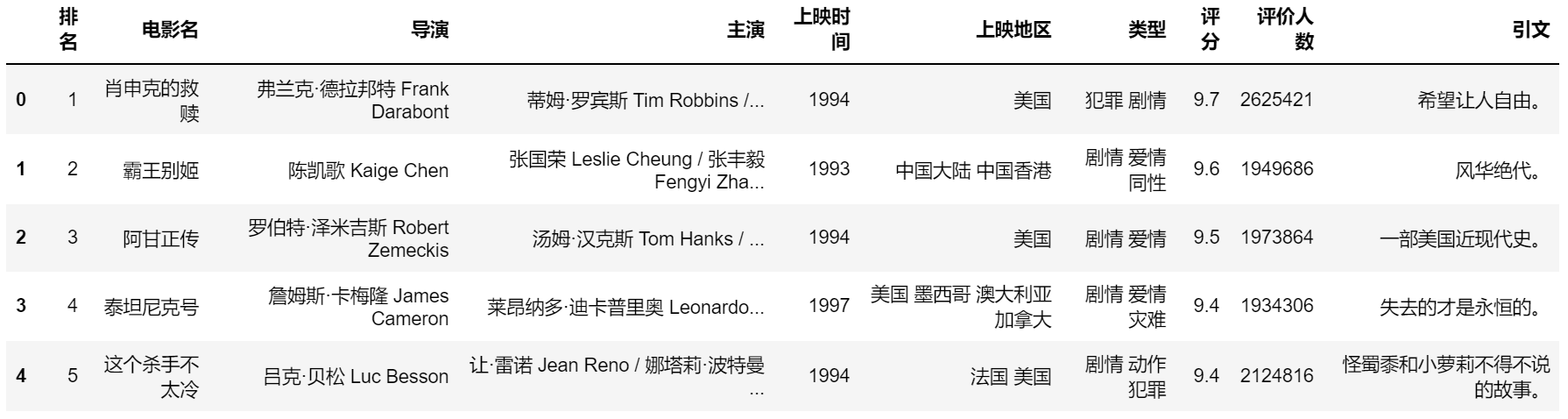
最终我们成功爬取到豆瓣电影Top250,数据如下:
4. 小结
相较前1个Case,这个Case的难点在于数据源是分页的,需要循环分页爬取,这时需要明确网址规律,然后将爬取代码封装成函数,循环调用这个函数并每次传递新的网址,从而实现循环爬取。
原创文章,转载请务必注明出处并留下原文链接。